
HTTP & WebSockets
*This is a mirror to the content posted onIn our last tech rendezvous, we delved into the realm of Simple Servers and got cosy with sockets-based communication - the unsung heroes behind the scenes. But let’s face it, when it comes to writing servers today, it’s the dynamic duo of HTTP and HTTPS taking centre stage!
Picture this: the entire digital cosmos, with terabytes of data zipping around every second to the gadgets in our hands - it’s mostly all orchestrated by the magic of HTTP and WebSocket. But here’s the kicker - how do they tango with sockets? How is HTTP evolving, and is WebSocket just a fancy cousin of the classic socket?
Hold on tight as we demystify these web wonders! I’ll be your guide, unravelling the tech tapestry with real-world examples and steering clear of unnecessary tech mumbo-jumbo. Let’s embark on a tech exploration where complexity meets simplicity! 🚀🌐💡
Prerequisites
A little knowledge of network systems with interest in the topic should be just excellent. Have a look at my last blog for some basic concepts.
Introduction to HTTP and its versions
Once a socket-based connection is made, the client and the server can indeed communicate with each other. If it were for your inhouse application, any form of communication standards would suffice. But, when it comes to standardizing a protocol for communication between the browsers and the servers, it ought to be simple and extensible. As you might know, HTTP plays that role. It is the underlying application-level protocol which defines this communication.
Whenever a browser wants a web page, it sends an HTTP request to get that page. The server responds according to this protocol and sends the page and an appropriate HTTP status code which can be interpreted by the browser as the standard server’s response. Its versatility and usefulness are reflected on its extensive use even now (since the 1990s). Today, a wide range of applications (almost just about anything you can think of) are deployed over HTTP.
HTTP is a request/response protocol. The client sends a request to the server in the form of a request method, URI, and protocol version, followed by a message containing request modifiers, client information, and possible body content over the connection. The server responds with a status line, including the message’s protocol version and a success or error code, followed by a message containing server information, entity metainformation, and possible entity-body content.
Features
- HTTP by itself is stateless. This means each request is executed independently, without any knowledge of the requests that were executed before it, i.e. the server does not keep any state between two requests. Even though servers use cookies today to store state, HTTP remains stateless
- The applications can easily modify it by adding custom headers, which the client and the server agrees upon.
- It is reliable (ensures the message is transferred or generates an error).
- HTTP/1.x, it is pretty easy to implement, something which I demonstrated in my socket blog.
Versions
Take the simplest example of HTML/0.9 (the initially proposed version). As simple as making a TCP Socket connection and sending one-line ASCII request
GET /index.html
to the socket will get you the response hypertext message from the server socket
<HTML>
<Body>
<h1>
Hello from server!
</h1>
</Body>
</HTML>
and the connection will be closed.
HTTP has had several revisions since. HTTP/1.0 modified HTTP/0.9 and added features like status code headers, version (appended in the 1st line).
Standardised in HTTP/1.1, it is the most widely used version right now. It introduced connection reuse, among other things. Opening and closing a connection is a significant overhead in a TCP connection. With the introduction of SSL/TLS Handshake, the number of message exchanges for establishing a connection has gone significantly up, increasing the load on HTTP servers apart from causing congestion on the Internet and the apparent delay. By persisting a connection, memory & CPU time is conserved as well. These warm existing connections overcome TCP slow start congestion control protocol as well. Hence, it’s wasteful if used for just a single request-response exchange connection.
Using persistent connections, multiple HTTP requests could be sent in the same connection (connection is ‘keepalive’ by default). This allowed connection to be reused, but the problem remained that newer requests had to wait for the response of the existing one in a particular connection(a strict FIFO from the client-side).
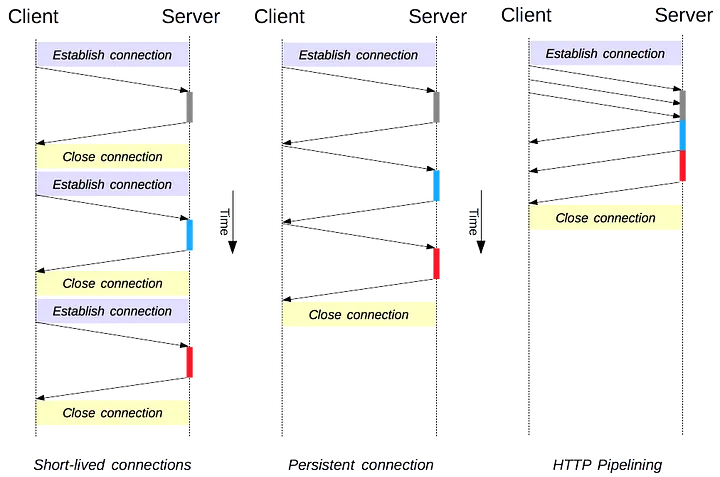
It introduced request pipelining as well wherein, multiple requests could be sent instead of waiting for the response of the first one to arrive, on the same connection. Modern-day webpages request tons of other static assets as well upon loading. Pipelining them on the same connection makes sense as well. But this increases the load of buffering and processing on the server’s end. As you can see in the picture, the server can only send the response to a request in a FIFO manner. Multiplexing was still not introduced for helping with multiple parallel responses. This has some other severe implications in TCP based connection as well. Therefore pipelining is in marginal use today.
In such a scenario, browsers have limited choice for handling tons of static resources put into displaying today’s web pages. They have to make a balance between the number of parallel connections and FIFO delay. (Throwing unlimited connection may lead to unintentional D-DoS). In practice, browsers tend to open around 6 connections per host, but there is a good discussion around that. From RFC 2616, “Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy”.
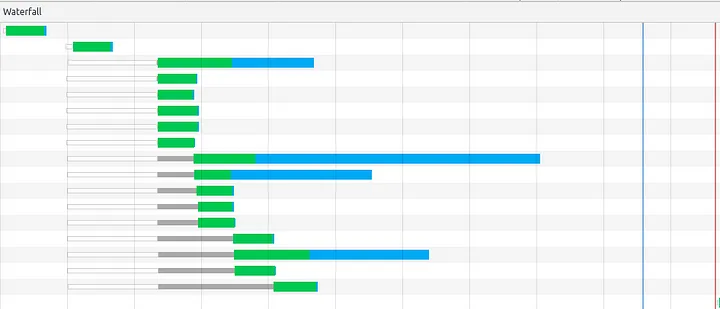
Waterfall for the same domain using HTTP/1.1
You can verify this using the inspect-network tool in the (chrome) browser. Notice how only 6 parallel connections are made (to the same host) and other requests are waiting for the response to the earlier ones.
There is yet another problem with HTTP/1.x. When considering tons of HTTP calls for a single page rendering, everything matters. If you notice, we are exchanging a bunch of metadata including headers and cookies(which by the stateless nature needs to be sent with all of your requests) which fundamentally increase the total payload for the transport layer. These are sent as plain text without compression. Run the command:
curl --trace-ascii - 'http://postman-echo.com/get?foo1=bar1&foo2=bar2'
You can see that the header to data byte ratio in the request is 103:0, whereas in response is 352:227. Headers clearly overshadow the actual HTTP payload.
Come HTTP/2.0, many of these problems were addressed. Essentially it adds a new intermediate binary framing layer between the HTTP/1.x syntax and the underlying transport protocol, without fundamentally modifying it. With the introduction of multiplexing transfers, multiple requests could be sent simultaneously in the same TCP connection with each request being largely independent of others in the form of separate streams. These streams are just a bidirectional flow of HTTP/2 frames, identifiable by assigned integers. Multiple streams can be initiated and used at the same time within the same connection, thus establishing multiplexing.
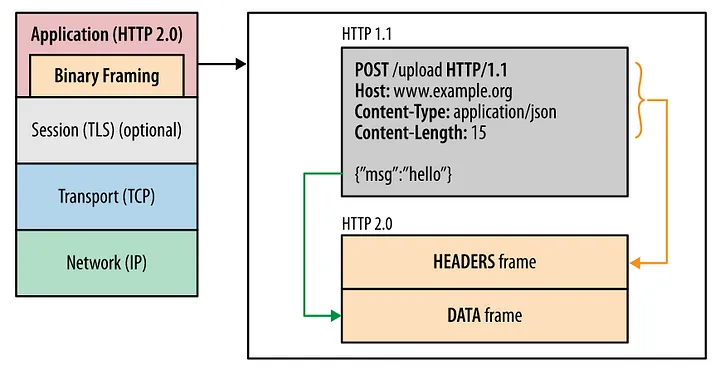
The basic protocol unit in HTTP/2 is a frame. There are quite a few types of frame, including HEADERS and DATA frame. The format of frames is well defined in RFC 7540. Along with other stuff, these frames carry a stream identifier, necessary while multiplexing wherein these frames of different streams can be interleaved and then reassembled. In the HEADERS frame, headers are compressed and serialised into a header block using HPACK compression. Often these header names and values are the same or similar. It uses Huffman encoding and static and dynamic reference tables for this purpose. Same headers among consecutive frames can be simply referenced using the dynamic table and duplicates can be dropped. You can get a feeling of how this would be done and feel the compression gain as well. Header frames may also contain a weight field, assigning priority to the requests. This prioritisation will help in getting crucial assets like CSS and blocking JS faster, thus improving performance.
With the introduction of server push, servers can push additional resources to the client which it knows the client would request for. The server can send these in additional multiple responses (in new push streams) for the single request. This indeed helps in saving request latencies in RTT (Round Trip Time). For example, the server may push all the relevant assets when it receives a request for the index page, which the client can cache.
Standardised in 2015, HTTP/2 has seen wide adoption, particularly with high traffic servers. The protocol requires no change from the web application but only an upgrade to the browser and the server. The application side API remains the same with the same semantics. Because the data is transferred using binary instead of text, tcpdump cannot be used to read the data directly. As such it can run with TLS or as cleartext TCP but is generally used with HTTPS.
Check the latest implementations of HTTP/2 here. As a fact, Medium is using H2 as of now!
Implementation
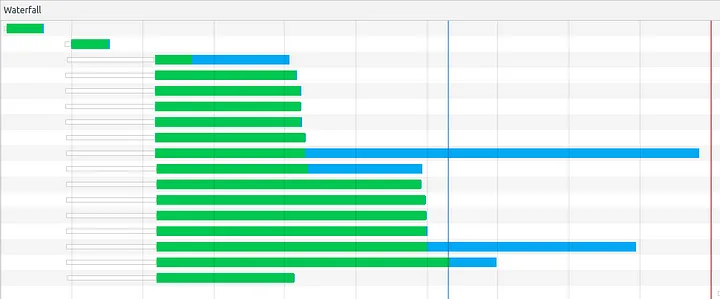
Waterfall for the same host using H2
Clearly HTTP/2 is vastly different wrt HTTP/1.1 (from the image far up), you can see that the time for the first two items remained almost similar (owing to the way the page is loaded), but after that 15 more assets are requested at the same time. You can see that in HTTP/1.1, requests were queued in 6 parallel TCP connections waiting for their turn, but here, all of them are requested at once (with set priorities) without waiting. Notice how the only JS request (3rd one) took less (626 ms) to load from the HTTP/1.1 (734 ms). This can be attributed to high priority being assigned to the blocking JS assets by chrome. As for the increased size of the green bar (time to first byte) for others, it is because HTTP/2 prioritises critical JS assets for a better experience, so other requests have to wait for a while. Also, do note that the finish time is 2.30s in HTTP/1.1 vs 2.12s in H2

With Server push
For the image above, I pushed CSS and JS assets (2nd and 3rd, respectively) with the index page (1st request). Notice how it makes no network call for these resources as gets it from the cached files (pushed from server). This is a significant boost in performance and user experience wrt other images above.
Let’s move to the more recent and under-development, HTTP/3 (HTTP over QUIC(Quick UDP Internet Connections)). Though much support is not available, popular browsers and servers are slowly adopting HTTP/3. QUIC, unlike other revisions, is somewhat radical. The whole concept is to shift the entire protocol from TCP to UDP! Yes, you read it right.
Owing to some of the limitations of the underlying TCP at the transport layer, it became crucial to think of modifying that protocol. But then modifying TCP would have required changes in the entire internet infrastructure. Therefore, this new transport layer protocol is built upon UDP and inherits properties from TCP with modifications as needed.
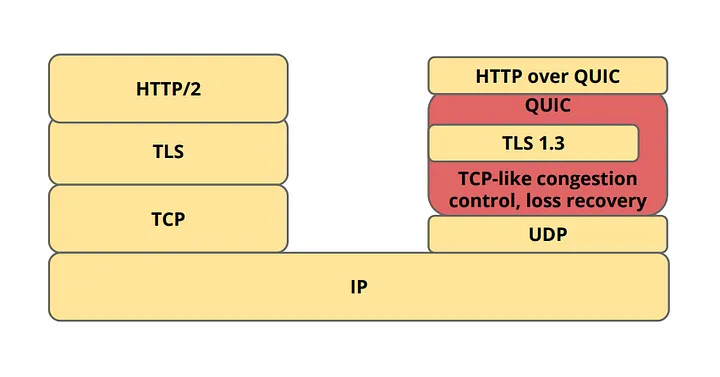
To count a few limitations of TCP, wrt HTTP/2.0:
- Connection establishment latency: For a general TCP secure connection, it requires 2–3 RTT in handshakes whereas it can be done in 0–1 RTT in QUIC. It merges connection and encryption into a single handshake. If the client has talked to a given server before, it can start sending data without any round trip!
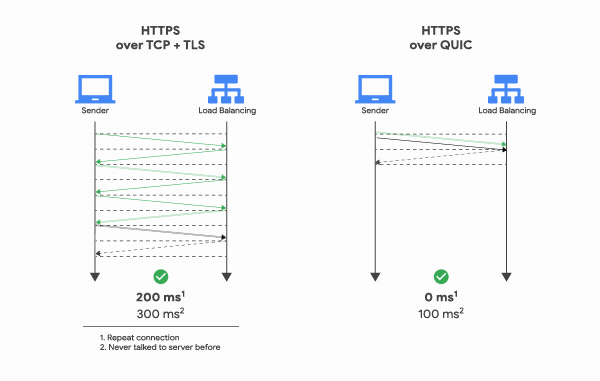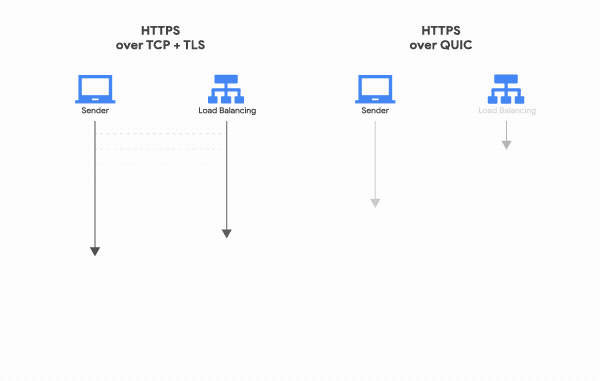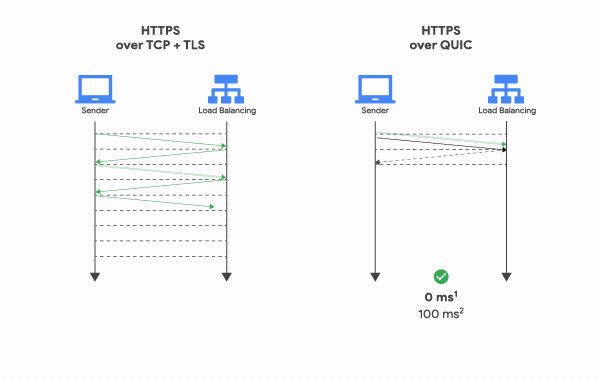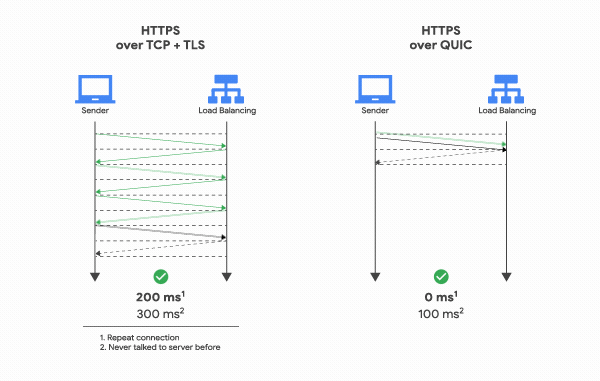
- Encryption: QUIC comes with encryption built into it and negotiates the terms in its only Handshake (TLS 1.3). Connections are encrypted from the beginning.
- Stream control: In HTTP/2, wherein multiple streams utilise a shared connection, the underlying TCP has no idea of these streams. Consequently, the transport layer values them as consecutive payload sent by the application layer. This can cause some limitation such as Head of Line Blocking wherein all the streams can be blocked until a previously on flight stream frame has not been received. This is essentially handled by bringing the pre-stream control to the underlying QUIC protocol.
- Connection migration: Switching networks in HTTP/2 would mean inflight packets being dropped and the need to establish a new connection (because a socket is identified using IP address port pair). This would be handled in QUIC using a 64-bit connection ID. This will help a server identify a client even when the client changes its IP address (like switching to Wi-Fi from a cellular network).
QUIC streams, like HTTP/2 streams, share the same connection. Additional control over independent streams provides additional advantages. Streams can now arrive out of order among each other and are not affected by network packet loss of another stream. However, this has to lead the HPACK algorithm to be modified into QPACK for HTTP/3, because this out of order delivery can cause some additional issues. QPACK uses separate unidirectional streams to modify and track header table state. The new HTTP/3 is built over this protocol. HTTP/3 streams simply run over QUIC streams. The semantics has not changed and is yet transparent to the application.
Much of the work is yet to be finalised, and various implementations spring up similar to the draft proposal. Check the latest implementations of QUIC HTTP/3 here.
Is WebSockets the same as Sockets?
WebSocket is a communication protocol that allows clients(like browsers) and servers to communicate on a full-duplex channel over a long time over TCP Sockets. Being based on a persistent TCP Socket connection, any of the client or the server can send data at any time until the connection is broken from either of the parties. Think about building a chat application. Pinging Server continuously for checking for new messages would be a waste of bandwidth and resources. The server should be able to respond by itself when it gets new data to send. This also differentiates WebSockets from HTTP persistent connections.
WebSockets and Network Sockets may sound similar but are quite different. While the latter is just a generic file descriptor to the file where the network writes the received data packets the former is a protocol built upon TCP Sockets. Network Socket, in general, is independent of the transport protocol(TCP or UDP).
This protocol requires a handshake over the established TCP Socket connection. The Handshake is based on simple HTTP request-response and an upgrade header and other related fields.
The handshake from the client looks as follows:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Origin: http://example.com
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
The handshake from the server looks as follows:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: chat
If everything is fine, the connection is upgraded to a WebSocket connection after which any party can send data as required. Thereafter, the same connection is used for exchanging any further message. Various other control frames like PING, PONG, CLOSE are used to check/ close the connection
There are various libraries available to abstract the working of WebSockets.
Conclusion
🌟 Nailed the Basics! 🚀 Now, brace yourself for the exciting part – the promise of HTTP. Curious about the security dance? Dive into my next blog on HTTPS and TLS-SSL. The adventure continues! 💻🔒
How is the HTTP traffic secured? What does that lock indicate? How do we establish trust? How can I say that indeed medium.com…
See you there!
read more...